
In my last EDMCS post, we talked about the differences in data governance features between Oracle DRM and EDMCS. Today’s post will go into more detail on the overall data model – “Data Chain” – of EDMCS.
The way data is maintained and stored in DRM and EDMCS varies quite a bit. DRM data, at a high level, is summarized as this:
DRM Data:
- Hierarchies are made of Nodes (records)
- Versions of made of Hierarchies
- Hierarchies may or may not be in a Hierarchy Group
- Nodes may or may not be assigned a Node Type
- Property Definitions can be used across all Nodes, only visually limited by Node Type in end-user interface
EDMCS is completely different in its data setup; in that the data is contained, maintained, validated, and filtered differently. Although the application is still contains a foundation of nodes, hierarchies, and their attributes, the configuration of the data is more robust:
EDMCS “Data Chain”:
- Node Types define all Nodes (records)
- Hierarchy Sets consist of one or more Node Types
- Node Sets are defined from Hierarchy Sets
- Viewpoints are generated from a Node Set
- Views consist of one or more Viewpoints
- Property Definitions applicable for the Nodes are defined at the Node Type level
DRM Data vs. EDMCS “Data Chain”
| Feature | EDMCS | DRM |
| Data is required to have a Node Type | Yes | No |
| Node Types limit Property Definition usage by Subject Matter | Yes | No |
| Node Types can have relationships and hierarchies | Yes | No |
| Data validations can be specific to target application | Yes* | Yes |
| Master data can be filtered by target-system view | Yes | No** |
* EDMCS currently does not have any custom validation options, but has some built-in for specific target systems
** Hierarchies are in target system view if no filtering/membership is needed
Below is a graphic from the EDMCS administrator guide, visually showing the EDMCS data chain for two types of subject matter areas: Employees and Departments:
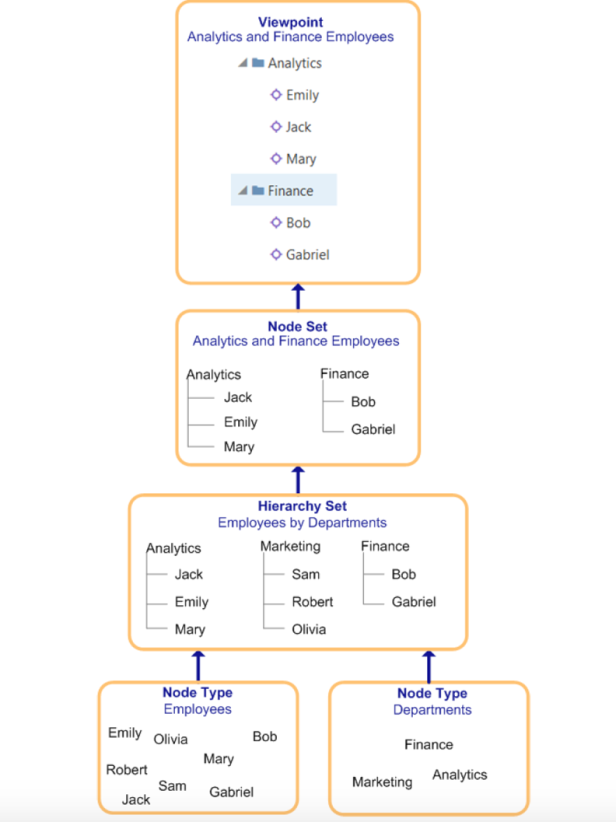
For more information about the components of the EDMCS Data Chain and how they relate to DRM concepts, read on:
EDMCS Node Types
Node Types, similar to DRM’s Node Type feature, defines nodes in the application that have common attributes or subject matter. Accounts, Entities, or Employees could be considered Node Types. Unlike DRM, in EDMCS all nodes are required to have a Node Type.
Also, the configured Node Type determines the properties/attributes that are available for the node. This is also different from DRM, as Node Types are only a visual filter for users – the Node Type “shows” which properties are relevant for the node, but in realty all DRM properties are available and exportable for all data/nodes in the application.
Another difference between DRM and EDMCS for Node Types is that EDMCS allows the Node Types to have a type of “hierarchy” – where you can have a main Account Node Type, then maybe GL Accounts or Plan Accounts be “sub” Node Types.
Node Typing, in a way, is similar to how we use prefixing in DRM – each node is uniquely identified by the Node Type and its name. So, in theory, if you have an Account 10000 and an Employee 10000 – as long as the Node Types are identified separately, the nodes are separate data points.
Also, EDMCS allows for Node Types to be converted to other Node Types for comparative purposes. For example, if you have multiple Account Node Types, such as Consolidation Accounts and Planning Accounts, but you want to compare them; you may have to create a converter to convert the Planning Accounts to Consolidation Account Node Types to complete the comparison. This is different from DRM, which allows the user to compare any type of data based on structure, name, or other property parameters.
Hierarchy Sets & Node Sets
Hierarchy Sets define the parent/child relationships or determine relationships between Node Types. Hierarchy sets determine how data rolls up. Hierarchy sets, also, define any mapping tables between Node Types that may be needed for downstream applications.
For example, say you have 3 types of Account Node Types: Reporting, Base GL, and Planning. You may define in the Hierarchy Set that Base GL and Planning nodes can be children of the Reporting Node Type.
Node Sets take Hierarchy Sets one step further, and define the list of valid nodes for the downstream Viewpoint/application. For example, if you had a list of all valid Account nodes in the Hierarchy Set, but the downstream application only needed Income Statement Accounts, the Node Set would be where this filter is applied, to only show Income Statement Accounts in the resulting Viewpoint.
These pieces are relatable to the DRM Export hierarchy selection and filter logic – which determine the applicable hierarchies and apply any filters based on attributes (like membership properties).
EDMCS Viewpoints & Views
Once a Node Set has been applied, the result is called a Viewpoint. The Viewpoint is all qualifying Subject Matter area that makes up a dimension/export for a target application. An example of a Viewpoint would be the final Accounts for FCCS; or the Entity dimension for Planning/PBCS.
The main value and difference that I see here vs. DRM, is that the resulting Viewpoint is going to look exactly like it should in the target application. In DRM, we often use membership properties or filters on export to filter nodes in and out of the target application export – which can sometimes be confusing for end-users. The EDMCS Viewpoint is a visual view of everything qualifying for the target application, exactly as it should look in the target application. Much more user friendly!
Finally, Views consist of one or more Viewpoints. Thus, a View could be the Viewpoints of Account, Entity, and 2 Custom Dimensions for FCCS – all application metadata updates that are needed for a target application.
